被AI夺走工作的人,决定反抗AI|深氪lite
来源网站:www.sohu.com
作者:36氪
主题分类:劳动者权益事件
内容类型:深度报道或非虚构写作
关键词:原画师, 版权, 训练, 作品, 模型, 公司
涉及行业:体育休闲/文化娱乐, 服务业
涉及职业:青年学生/职校/实习生, 白领受雇者
地点: 北京市
相关议题:
- 生成式AI在绘画领域的应用导致原画师的工作机会减少,稿费降低,引发了一些原画师的不满和抵制行动。
- 一些原画师担心自己的作品被AI侵权,认为AI的生成过程涉及侵权行为,称AI作图没有灵魂,是尸体。
- 一些大公司的AI模型库被指控侵权,画师们联合起诉,希望为AI绘图的版权纠纷提供参考案例。
- 一些插画师对平台使用他们的作品作为AI训练素材表示不满,选择撤离平台以示抗议。
- AI绘画的发展让一些插画师失去了对绘画的热情,认为创作变得廉价了。一些插画师选择抵制AI,不希望自己的作品被用来喂养AI。
以上摘要由系统自动生成,仅供参考,若要使用需对照原文确认。
文|林炜鑫
编辑|苏建勋
AI=癌?
在大部分人因为AI进步欢欣鼓舞的时候,有一群人决定反抗AI。
过去一年,生成式AI让人类在绘画上节节败退。入行五年的游戏原画师石露说,今年的变化要超过以往任何一年。许多游戏开发公司都在使用AI,缩减美术团队。AI狂飙的几个月内,原画师的稿费从2万/张降到4千/张。
一些中低级的原画师给AI打工已经成为既定事实——大多时候,甲方一天生成100多张AI角色图,而石露和同事则负责给AI修图。
“前两周我还能给角色改脸或者改表情,”石露说,“这周的任务是画鼻毛和黑头。”多年前当实习生时,她已经可以画游戏角色形象,现在“日子一天不如一天”。她认为导致画师处境艰难的元凶便是AI。
“那是癌。”她说。在互联网上,反对者还给支持AI的人取了外号“癌哥”。

抵制AI绘画的logo(图源自网络)
人与AI的矛盾正在激化。许多画手担心被AI侵权。他们相信,文生图的原理就是“碎尸拼接”——开发者投喂了大量人类创作的画作给AI模型,模型将其打碎,再拼接,最后生成新的图。(尽管一些技术人员站出来辟谣,但无济于事。)
反对者形容AI作图没有灵魂,是尸体,喜欢AI作图就是“恋尸癖”。“拼接论”是他们的武器,以普通人的直觉来看,AI生图的过程已经涉及侵权。
推广AI的大公司们也陷入争议的漩涡。
2023年11月29日,四位画师联合起诉小红书AI模型库侵权,理由是小红书的AI图像创作工具Trik,疑似用了他们的作品去训练AI模型。
其中一位名叫“正版青团子”的画师,晒出两张插画,分别是她的作品和Trik AI生成的图。“无论是配色元素还是画面风格都和我的图很像,感觉心血被剽窃了。”她写道,“希望大家一起维权。”

青团子作品(左)与Trik AI作品(右)对比(图源自截图)
一位粉丝说,Trik AI所谓的中国风图片,“就是对国内古风太太们的图大量投喂,好多(Trik)生成的古风场景都有熟悉的太太们的感觉”。(“太太”是圈内粉丝对厉害画手的昵称)
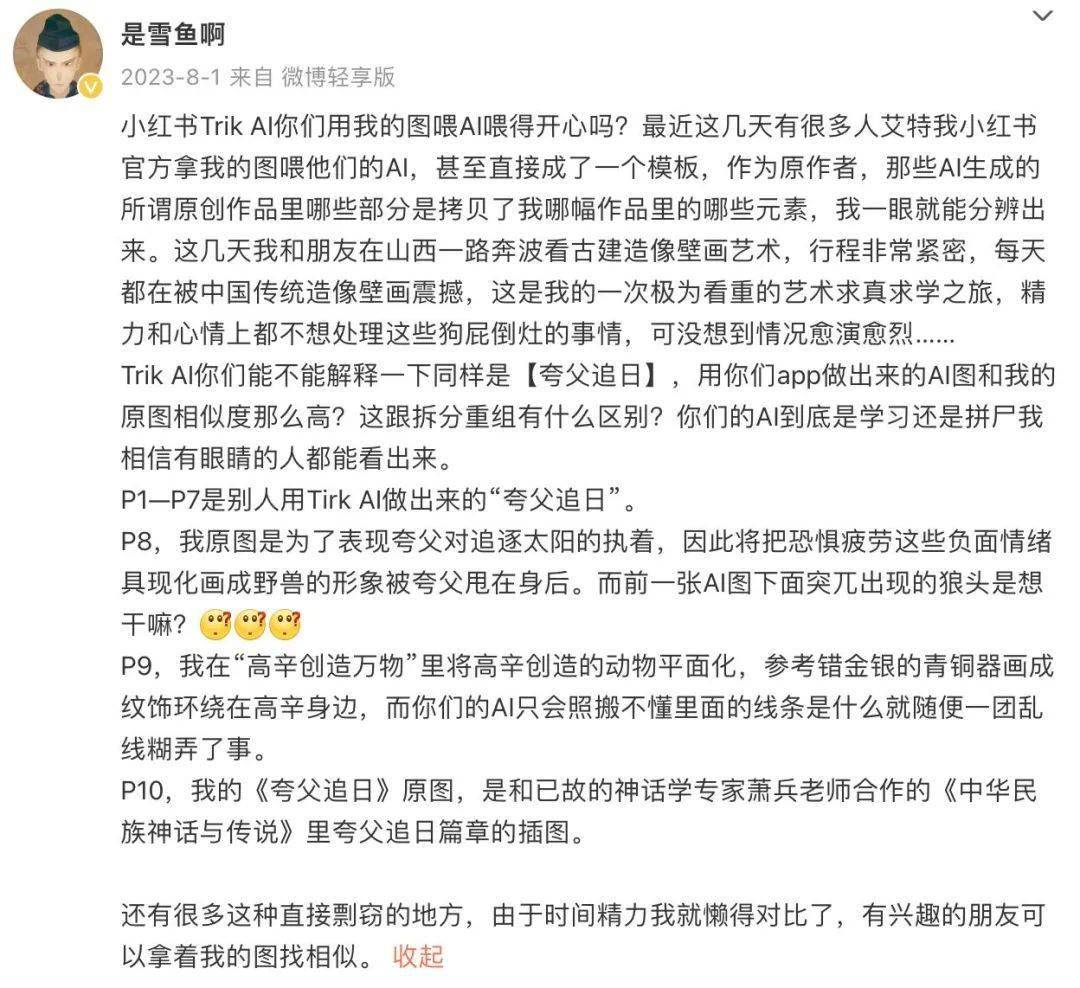
画师“是雪鱼啊”将Trik AI生成的图与自己的作品对比,认为两者相似度很高,甚至有类似的元素,他向小红书喊话,“你们用我的图喂AI喂得开心吗?”
雪鱼微博

雪鱼作品(左)与Trik AI作品(右)对比(图源自雪鱼微博)
他宣布在小红书上停更,理由是小红书未经允许,擅自将他的作品“喂”AI,以及平台近乎霸王条约的用户协议,引起他的不安。
起诉小红书的案件已在北京互联网法院立案。据了解,这是国内第一起针对AIGC训练数据集侵权问题的案件。
小红书方面以案件进入司法程序为由,拒绝发表评论。青团子透露,立案之前,小红书的人曾找过来,希望协商。但他们已经约定不接受调解,坚持立案。青团子说,希望这案子能为AI绘图的版权纠纷提供参考案例。
网易旗下LOFTER是画师与粉丝常用的交流平台,插画师高悦经常在LOFTER分享自己的作品,积累了一定的粉丝。去年她注意到LOFTER正在内测一项AI功能“老福鸽画画机”,用户只需使用关键词就能生成绘画作品。她忍不住怀疑平台会暗自将他们的作品变成AI的训练素材。

新功能“老福鸽画画机” (图源自截图)
“我对这个平台的信任度瞬间骤减,不寒而栗。”高悦说。
眼看越来越多的用户表达不满,LOFTER官方几天后删除了新功能的活动通告,并且声明训练数据来自开源,并未使用用户的作品数据。然而这项功能并没有第一时间下线,这也是无法让用户信服和放心的重要原因。
一番纠结之后,高悦选择响应部分创作者的号召,清空自己的账号,随后注销,以此表示抗争。在高悦看来,从平台撤退,是目前为数不多的自我保护的方式。
“我不希望公开发布作品,去喂养那个可能会取代我的怪物。”她说。
争议在设计师圈层越滚越大。上个月,龙年春晚吉祥物“龙辰辰”,也被质疑是AI作图——每只龙爪的脚趾数量不一样;嘴巴勾到鼻子上;龙鳞时而单层时而双层。春晚官方深夜发微博回应,“设计老师的头都秃了一块”,还晒出了吉祥物的设计过程。
央视春晚的回应(图源自微博截图)
插画师马群回忆,2022年AI绘画火过一阵,当时AI的画经常翻车,比如将人画成狗或马,很容易识别。后来AI进步的速度超出想象,但仍然有迹可循,比如AI还不懂如何画手。
坏消息是,上述漏洞短时间内逐渐消失了。马群认为,鉴别AI越来越依靠人的主观感受,“没有灵性”,或者“有一种非人质感”。
马群也抵制AI,因为AI让她失去了对绘画的热情。她不是科班出身,靠热情去自学绘画,大学毕业后,她成为一名全职画手。绘画的过程有时很折磨人,但看到成果的那一刻,她的喜悦盖过一切。
而现在,AI抹掉了大多数绘画步骤,一切都在自动化,意味着马群花费几年习得的技巧与经验,在高效、强大的算法面前黯然失色。
“创作变得廉价了。”马群对36氪说。
到法院去
创作者将AI公司告上法庭,几乎贯穿了2023一整年。
在硅谷,新的技术风口并不罕见,此前的元宇宙、加密货币都曾备受瞩目,很快便不了了之。生成式AI之所以能在短时间内掀起声浪,是因为它看起来真的有用,足以颠覆旧世界,以至于让人感到巨大的威胁,比如手握版权的内容创作者。
率先向AI发难的是一位名叫卡拉·奥尔蒂斯的插画师。她也是“拼接论”的信徒,面对在绘画领域攻城略地的Stability AI,她的脑海里只浮现出两个词:剥削、恶心。那段时间,一些工作机会被AI无情夺走,她陷入焦虑,继而决定反抗。
她向律师马修·巴特里克求助。2022年冬天,巴特里克为一群程序员提供法律帮助,后者认为微软的GitHub Copilot涉嫌侵犯他们的版权。巴特里克指责GitHub Copilot“窃取了程序员的工作”,积极地准备这场诉讼。2023年1月,巴特里克代理了奥尔蒂斯起诉Stability AI的案子。
类似的诉讼屡见不鲜。图片公司Getty Images分别在美国和英国起诉Stability AI,指控其非法复制和处理了1200万张Getty Imagas的图片;以乔治·马丁、乔纳森·弗兰岑为首的小说家们向OpenAI发难,而一群非虚构作家则把矛头对准OpenAI和微软;环球音乐等一众音乐厂牌声称Antropic在训练过程中非法使用了他们的版权作品,并且在模型生成内容中非法分发了歌词。
2023年12月27日,《纽约时报》正式起诉微软和OpenAI,宣称报社数百万篇文章被用作AI的训练数据,而AI正作为新闻消息源与报社竞争。
一场围绕AI版权的全面战争已经打响,难题纷纷抛给了各国的法院。
在中国,一桩AI绘图侵权案,从立案到判决,持续了数月,是其他图片侵权案处理时长的数倍。
2023年2月,原告李昀锴在百家号的文章发现自己用AI创作的图片被用作配图,但文章作者使用时未经许可,并且裁掉了李昀锴的署名水印。于是李昀锴以侵犯署名权和信息网络传播权为由,向北京互联网法院起诉该作者。
案件本身并不复杂,但是,由于被侵权的图片是AI模型Stable Diffusion生成,引起了大量关注,被网友称为“AI绘图第一案”。

被侵权的图片,是李昀锴用AI生成的(图片由受访者提供)
李昀锴不是设计师,他是一名知识产权律师,入行将满10年,职业生涯大部分时间,他都在研究新技术与版权法之间的博弈。去年9月他开始研究AI绘画工具,并尝试用Stable Diffusion生成图片,研究之余还在小红书分享用AI生成的图片。
有天,李昀锴发现他用AI绘制的图片,出现在一篇百家号文章里。这是明显的侵权行为。出于职业兴趣,他想弄明白AI作图的版权归属,更重要的是,法院到底会怎么想?
挪用李昀锴图片的人、也是此案的被告,是位五六十岁的女性,自称身患重病,收到法院通知时一头雾水。在庭审上,她解释那张图片是通过网络搜索获得,具体来源已经无法提供。
她还说,AI绘图是人类智慧的结晶,不能算是原告的作品。这也是该案争论的焦点,AI生成的图片是否构成作品,以及李昀锴是否享有该图片的著作权。
对各国来说,这都是一个悬而未决的法律问题。去年八月,美国一家法院判决,机器创作的内容没有版权,原因是“人类作者身份是版权的基本要求”。但这个结论很快受到质疑。有人指出,同样是使用机器,如果用手机拍照,照片就能受版权保护,用AI模型生成图片,理应也有版权保护,不是吗?
针对该问题,北京互联网法院则作出了截然相反的判决。
审理此案的法官要求李昀锴详细演示用AI生成图片的全过程,包括下载软件、写提示词等。为了让法官了解AI技术,李昀锴查阅了很多资料,尽力向法官解释AI绘画的原理和创作过程。
法官最终认为,李昀锴在涉案AI图片的创作过程中,做了很多智力介入,这体现了作品的独创性。因此这幅AI图片被认定为李昀锴的作品,享有著作权保护。
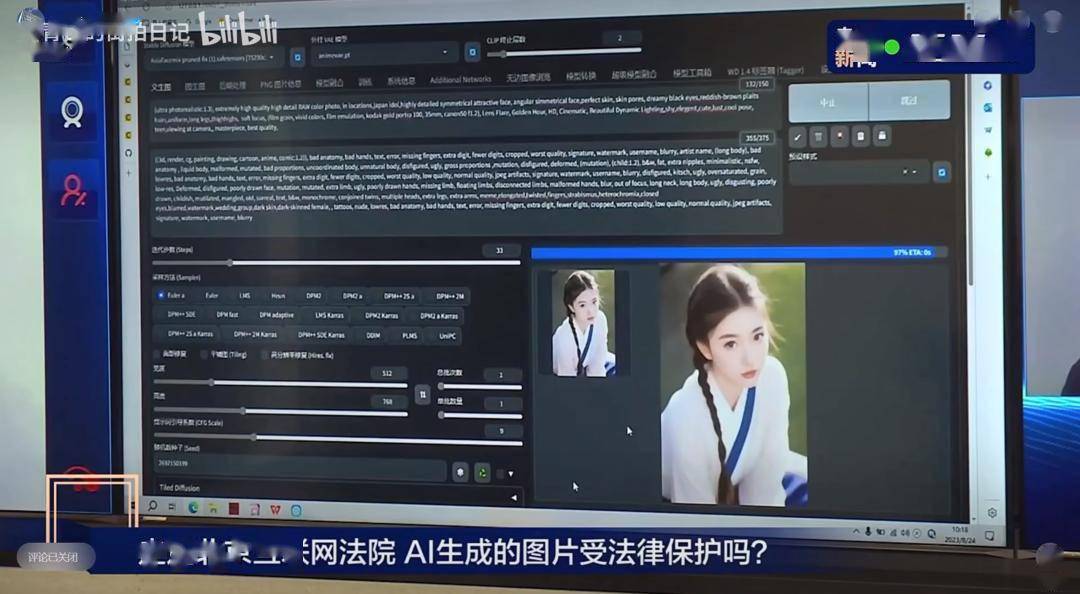
2023年8月24日庭审全网直播(图源自视频截图)
李昀锴告诉36氪,这个判决让国内一些正在观望的AI公司“喜忧参半”,开心的是AI生成的图拥有版权,忧愁的则是,版权看起来是归属于用户。
AI公司并不慌
作为版权争议的另一端,AI公司显然无心恋战。客观上说,版权争议短期内吵不出结果,所以,回避甚至保持沉默是最稳妥的办法。
2023年12月,美图公司推出新一代大模型,号称具备更强大的视频生成功能。尽管公司高层强调,AI是一种辅助工具,不是要取代专业人士,但许多从业者相信,这些新功能假以时日会进一步威胁他们的工作机会。
在问答环节,36氪提出AI可能引发版权纠纷的问题,想知道他们将如何应对。
“AIGC生成图片的版权问题,实践中有争论,有赖于法律的进一步规范,”一位高管说,“虽然目前这方面的法律不是很清晰,但我们总体上会保护用户,尤其是专业人士的版权。”
另一位高管提到了“AI绘画第一案”的判决结果,表示认同法院的判断,“如果像‘AI绘画第一案’这种情况,我们也认为AI公司和AI模型不拥有相关版权。”
OpenAI今年在开发者大会上,高调宣布将为使用GPT而遭到法律纠纷的人承担诉讼费用。在部分创作者看来,这却像是在挑衅。
某种程度上,AI公司有恃无恐。起诉AI的最核心的主张——AI模型在使用训练数据时就已经构成侵权行为——并非无懈可击。一些AI公司把AI训练比作人类的学习过程,一个新学徒需要阅读,甚至模仿老师的作品,才能掌握技术。如果法院采纳这一观点,那就不构成侵权。
一位律师表示,AI公司很有可能会采用“合理使用原则”来作辩护。“合理使用原则”大概是指,虽然你的行为严格来说算侵权,但你的行为是一种可以接受的借用,用来促进创造性的表达。例如,学者可以在自己的作品中引用摘录他人内容;作者可以出版改编图书;普通人可以截取电影片段做影评。
换句话说,如果对版权限制过死,文明的创造力将可能停滞。
科技公司长期利用这一原则来规避版权争议。2013年,谷歌因为复制数百万册图书并在线上传书里的片段,遭到作家协会的起诉,法官基于合理使用原则,裁决谷歌这一行为合法,因为它为公众创建了可搜索的索引,创造了公共价值。
在大模型时代,合理使用原则仍可能发挥关键作用。支持AI不侵权的人认为,大模型生成内容的过程,跟人类创作相差无几——当你尝试画一幅画或拍一支视频,你的脑海里也会有你看过的画或电影。人类的创作在前人的基础上进步,大模型也是如此。
在美国,已经有法官表示支持Meta的主张,驳回关于LLaMA生成的文本侵犯作家版权的指控。
该法官暗示作家们可以继续上诉,但这将拉长诉讼的战线,这对AI公司也是一种利好。一位学者表示,随着AI产品越来越受欢迎,大众对AI的接纳程度在提高,这将导致法院必须更谨慎地作出判决。
更重要的是,AI的战略地位和商业价值不断上升,AI技术的信徒普遍担心,如果版权限制过严,将制约AI技术的发展。
李昀锴和一些大模型开发者交流过,对方表示主管机关的态度相对谨慎,是因为除了考虑个案,他们还要顾及中国AI的技术发展,以及国与国之间关于AI技术的竞争。
另一个障碍在于,AI公司在模型训练数据方面几乎没有透明度。
只需举一个近期发生的例子:2023年12月7日,Google发布了一份长达60页的报告,其中反复强调训练数据的关键性——“我们发现数据质量对一个高性能模型至关重要”,但几乎没有提供关于数据的来源、筛选以及具体内容的任何信息。
一位算法工程师对36氪说,他们寻找训练数据的方式无非是:用爬虫将互联网的内容爬一遍;找一些开源的数据集;实在不行就去黑市购买,“总能买得到”。
有学者讥讽道,AI公司与其去竞争模型在评测榜单的性能分数,不如比拼一下谁可以拥有最合法的训练数据。
不过,批评AI公司训练数据不透明,也有些苛责。毕竟训练数据将极大左右模型性能,是各家AI公司的商业机密。试想一下,可口可乐将他们的配方严格保密了137年,至今没有人破解,AI公司不会轻易交出他们的底牌。
在现有法律条文下,AI公司也没有义务和动力去公开训练数据。
李昀锴对36氪说,“国内没有证据开示制度”(该制度规定,只要与案件事实具有关联性的证据,当事人有权要求掌握该证据的其他当事人对其进行出示、披露),这意味着AI公司可以不披露模型的训练数据。“现在这个制度下,只要企业不披露,就没人知道有没有拿用户数据去训练。这是一个死结。”他说。
截至发稿,四位画师起诉小红书AI的案子仍未开庭。李昀锴正在关注此案,谈到胜败,他说:“画师的诉求有可能无法获得支持,因为他们没办法证明自己的作品被训练了。”
很遗憾,创作者要想在这场版权战争大获全胜,可能性微乎其微。
但这不代表AI公司可以完全不顾一切。舆论的影响也很重要。2023年11月, 金山办公开启AI功能公测,很快有人发现,产品隐私政策提到,为提升AI功能准确性,将对用户主动上传的文档材料,经脱敏处理后作为AI训练的基础材料使用。这一条款引起大量用户不满。
一位版权法律师猜测,公司法务写明上述条款,目的是“想尽量把这个事情变得合规”。当他们规避法律风险后,却陷入了舆论风险,多少有些黑色幽默。
几天后,金山办公作出回应,承诺“所有用户文档不会被用于任何AI训练目的”,以此平息这场风波。CEO章庆元接受晚点《LatePost》采访时说,条款是旧的,针对PPT板式的美化,并不涉及用户文档,没来得及更新,导致用户误解。
李昀锴说,AI相关的知识版权界定,目前只能在司法实践的个案探索,“普遍的共识是尊重商业实践,即法律不会过度介入企业的自主行为。如果有知识产权,一般原则是归属于开发者进行分配。”
腾讯混元模型在相关条款中约定,生成内容的版权归用户所有,但“仅供个人学习、娱乐使用,不得将其用于任何商业化用途”。李昀锴说,“其他公司就不是这么大方。”
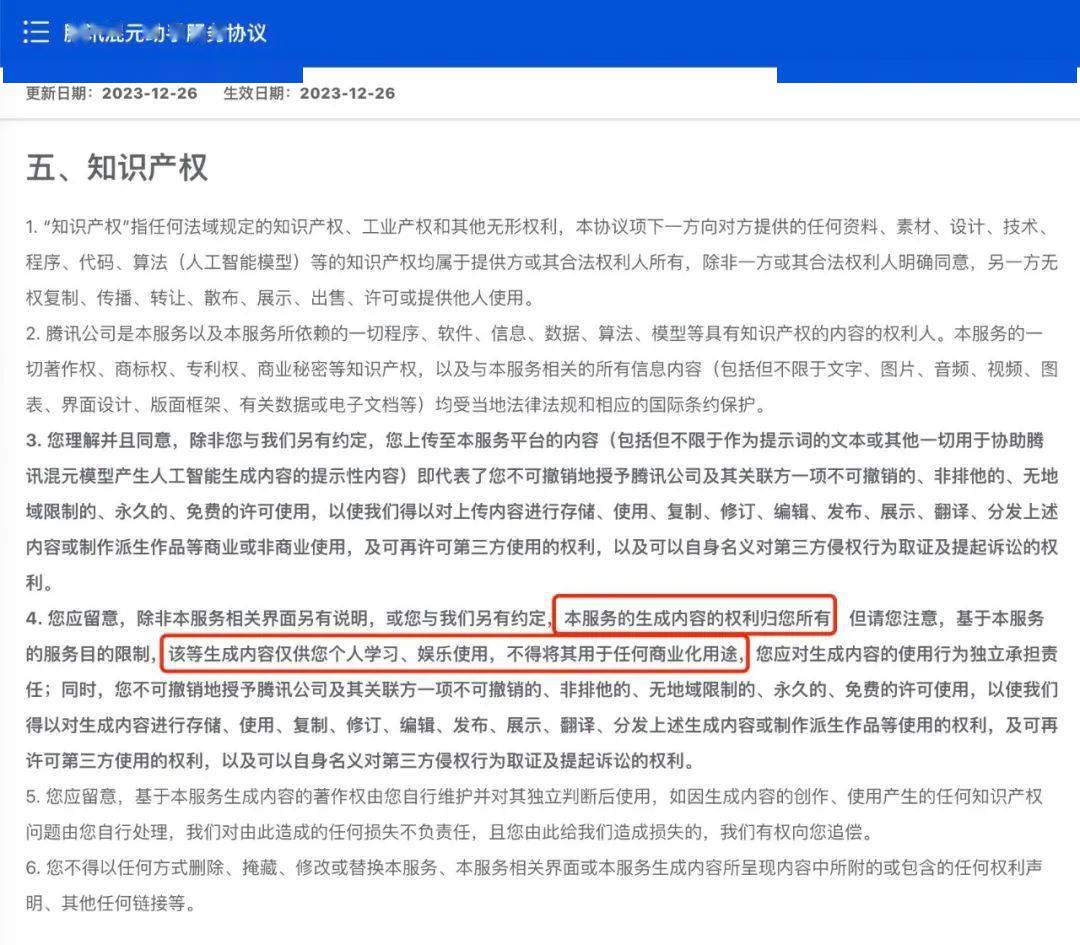
混元模型的相关条款(图源自截图)
目前呼声较大的一种妥协方案是,AI公司应该有一套解决方案去补偿内容创作者(参考Spotify给音乐人的补偿),如果作品被用作AI训练数据,创作者可以获得一定的费用。短期来看,这将保护创作者的利益。至于更长远会发生什么,谁也不敢保证。
2023年被称为“AI之夏”,AI公司成功地让更多人相信AI是大势所趋,包括一些内容创作者。前不久,《读库》主编张立宪在微博表示,2024年杂志扉页的图将全部采用AI绘画。
该条微博评论区引起不小的争议(图源自微博截图)
一位插画师留言:“最注重品质的读库接纳AI画作,意味深长。”
(应访谈对象要求,文中石露、高悦、马群为化名)返回搜狐,查看更多
责任编辑: